Big Data v prostředí MATLAB
Termínem „big data“ se rozumí taková data, která svým rozsahem či složitostí přesahují možnosti standardních výpočetních prostředků.
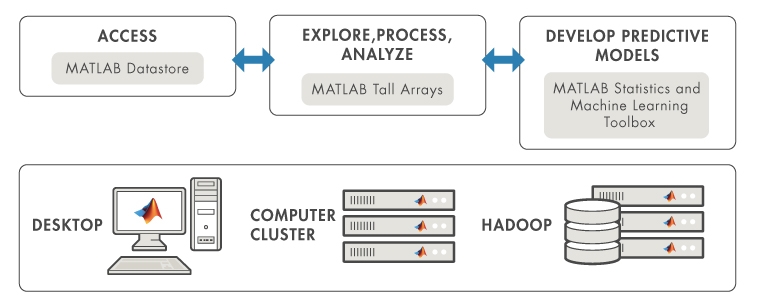
Přehled základních nástrojů programu MATLAB pro práci s tzv. big data najdete zde.
Narazili jste při zpracovávání dat na hranice výpočetních možností svého PC? Objevují se Vám chybové hlášky typu „Out of memory“ nebo trvá výpočet příliš dlouho? S podobnými problémy se dnes v oblasti datové analytiky setkáváme čím dál tím častěji. Množství dat, ke kterému máme přístup, totiž neustále narůstá. Ať už zpracováváme a analyzujeme tabulková data, text, obraz či signály, mnohdy velikost operační paměti našeho PC nestačí. Pro analýzu a zpracování je pak třeba mít k dispozici specializované funkce, které s takovým rozsahem dokáží pracovat.
MATLAB poskytuje celou řadu prostředků, jak s rozsáhlými daty pracovat. Od speciálních datových proměnných typu tall table, přes distribuovaná data, paralelní a GPU výpočty až po zpracování obrazu po blocích, streamovací algoritmy či stochastické optimalizační algoritmy při trénování modelů strojového učení.
Datastore
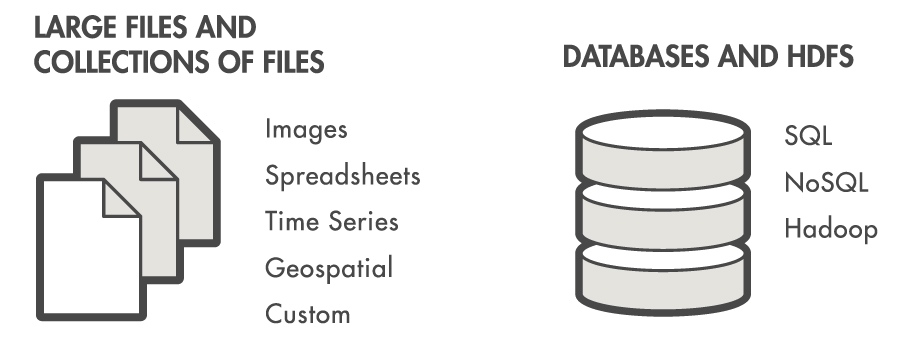
Při práci s daty, která se nevejdou do paměti jednoho počítače, je datastore základní datový typ. Umožňuje číst a zpracovávat data z mnoha souborů či tabulek jako jednu entitu. Data mohou být uložena v souborech na disku, vzdáleném uložišti (např. Hadoop), nebo s využitím Database Toolboxu i v databázi. Nevejdou-li se data naráz do paměti, umožňuje datastore jejich zpracování po částech s využitím funkce tall (Příklad) či cyklu while (Příklad).
Jak to funguje?
Pomocí funkce datastore zavolané na jména souborů, či adresářů,
vytvoříme proměnnou typu datastore, která funguje jako ukazatel na
data. Proměnná typu datastore má nastavitelné vlastnosti. Pomocí
nich lze například nastavit datové typy, zvolit velikost dat pro jednu
iteraci zpracovávání nebo vybrat pouze některé proměnné k načtení a
analýze. Kromě funkce datastore,
která je obecná, naleznete v dokumentaci i specializované funkce
TabularTextDatastore, SpreadsheetDatastore,
ImageDatastore, FileDatastore a databaseDatastore.
Specializované funkce přednastaví datastore pro příslušný
typ dat.
Datastore se často používá v kombinaci s funkcí tall nebo distributed, viz. níže.
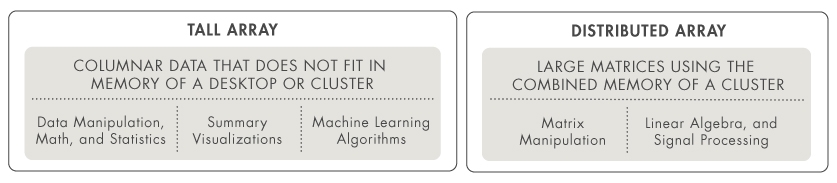
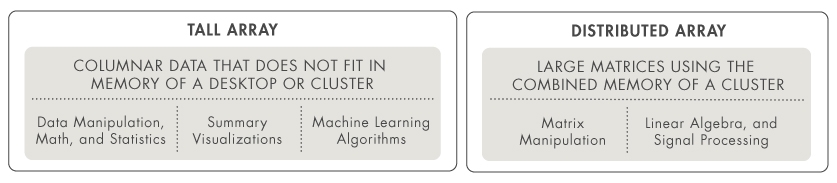
Pole s mnoha řádky – statistika a strojové učení
V případě, že data obsahují velký počet řádků a operace jsou povahou statistické, můžete datastore použít v kombinaci s tzv. tall array. Stovky funkcí ze základního MATLABu a Statistics and Machine Learning Toolboxu pak můžete na tall array volat stejným způsobem, jakým byste je volali na klasické pole načtené v paměti. Tímto způsobem lze například na velkých datech trénovat regresní modely či jiné algoritmy strojového učení.
Jak to funguje?
Na rozdíl od klasického pole v paměti zůstává proměnná typu tall
array nevyhodnocená a pouze si pamatuje operace, které je potřeba nad
daty provést, abychom ji vyhodnotili. Jakmile chceme tall array
vyhodnotit, zavoláme na ni funkci gather. Při vyhodnocení se pak
postupně po blocích prochází všemi daty. Některé funkce a operace
vyžadují vícero průchodu daty. Při zavolání funkce gather se
operace provedou tak, aby počet průchodů daty byl co nejmenší. Optimální
je tudíž vyhodnocovat všechny potřebné proměnné typu tall array
v jednom volání funkce gather.
Seznam všech podporovaných funkcí naleznete v dokumentaci zde. Více informací o tall array naleznete v dokumentaci.
Distribuované pole – lineární algebra
V případě, že chcete provádět například maticové operace a data se Vám dohromady vejdou na cluster složený z několika výpočetních stanic, můžete použít tzv. distributed array. Pro využití distribuovaného pole na výpočetním clusteru potřebujete Parallel Computing Toolbox a MATLAB Distributed Computing Server. Data můžete rozdistribuovat na cluster již při jejich načtení pomocí funkcí datastore a distributed. Příklad k tomuto naleznete zde.
Jak to funguje?
Data se rozdistribuují mezi jednotlivé výpočetní stanice, ze kterých se
cluster skládá. V MATLABu pak k datům nacházejícím se na clusteru
přistupujeme přes proměnnou typu distributed array. Na tuto
proměnnou lze volat stovky funkcí ze základního MATLABu stejným způsobem,
jakým bychom je volali na klasické nedistribuované pole. Interně se operace
provádí na výpočetním clusteru a v případě potřeby využívají
vzájemné komunikace mezi jednotlivými stanicemi. Díky paralelnímu režimu
spmd
(single program multiple data) můžeme přistupovat i přímo k jednotlivým
částem distribuovaného pole a paralelně na nich spouštět kód.
Seznam všech podporovaných funkcí naleznete v dokumentaci zde. Více informací o distribuovaném poli naleznete v dokumentaci nebo na našem školení Paralelní výpočty v prostředí MATLAB
{kind=link}
{kind=link}
Pro otestování možností prostředí MATLAB v oblasti datové analytiky Vám rádi poskytneme Trial licenci.
Jan Studnička (HUMUSOFT), 30.11.2018