Návrh riadiacich systémov metódou Reinforcement Learning
Umelá inteligencia už dlhšiu dobu mení náš pohľad na návrh algoritmov v rôznych oblastiach priemyslu. Medzi prvými sa vyvíjali algoritmy strojového učenia. V oblasti spracovania obrazu a signálov sa následne vďaka výborným výsledkom dostali do popredia konvolučné neurónové siete. Poslednou oblasťou, do ktorej umelá inteligencia preniká, je oblasť riadenia. Spoločnosti MathWorks ponúka v tejto oblasti samostatnú nadstavbu – Reinforcement Learning Toolbox.
Tradičný návrh regulačných obvodov využíva spätnú väzbu zo systému na stanovenie regulačnej odchýlky medzi želanou hodnotou a aktuálnym stavom systému. Na základe regulačnej odchýlky regulátor určí akčný zásah tak, aby sa systém dostal do požadovaného stavu. Hoci tradičná teória riadiacich systémov poskytuje niekoľko spoľahlivých metód návrhu regulátorov, nárastom zložitosti systému nemusí byť jednoduché regulátor navrhnúť. Zložitým systémom myslíme systém, ktorý sa nedá ľahko popísať, je vysoko nelineárny, obsahuje veľa stavov alebo na jeho riadenie potrebujeme niekoľko interagujúcich vnorených slučiek.
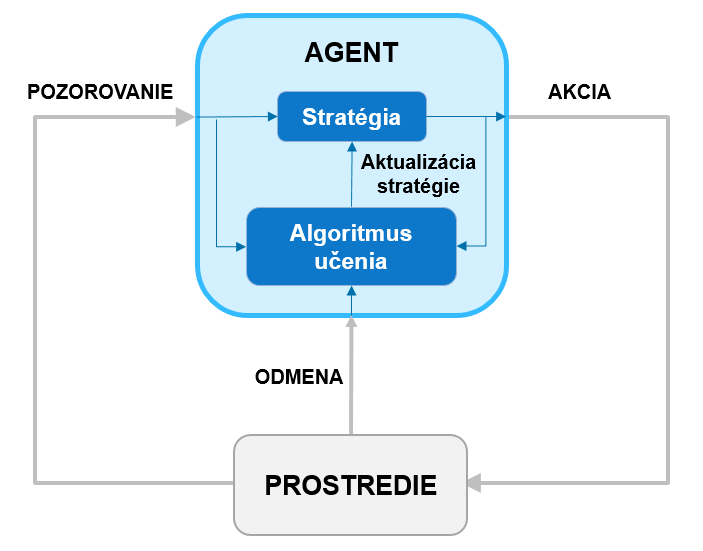
Riešením spomenutých problémov môže byť metóda reinforcement learning. Reinforcement learning je súčasťou strojového učenia, avšak namiesto statických dát využíva dynamické prostredie. Jeho cieľom je nájsť akcie, ktoré vedú na optimálne správanie sa natrénovaním agenta. Agent obsahuje stratégiu (aproximačnú funkciu), ktorá prijíma pozorovania (stavy systému, vstupy) a mapuje ich na akcie (výstupy). Okrem stratégie obsahuje agent učiaci sa algoritmus. Prostredie generuje pre agenta odmenu a určuje mieru úspešnosti akcie vzhľadom na splnenie cieľa úlohy. Učiaci algoritmus neustále aktualizuje parametre stratégie na základe akcií, pozorovaní a odmien. Cieľom algoritmu učenia je teda nájsť optimálnu stratégiu, ktorá maximalizuje kumulatívnu odmenu získanú počas úlohy. Reinforcement learning typicky obsahuje nasledujúce kroky: vytvorenie prostredia, definícia odmeny, vytvorenie agenta, trénovanie agenta a nasadenie stratégie.
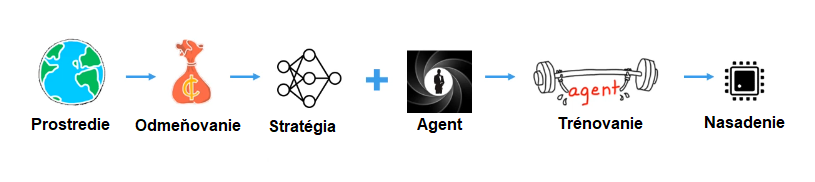
Vytvorenie prostredia
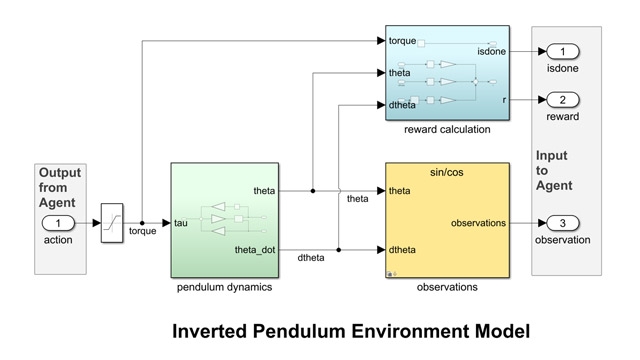
Ako sme už spomenuli na natrénovanie agenta potrebujeme prostredie. Oproti tradičnému riadeniu je prostredie všetko okrem agenta. Ako prvé teda musíme stanoviť, ako bude reprezentované prostredie. Prostredie môže byť skutočné fyzikálne prostredie (napríklad hardvér), alebo simulačný model. Využitie reálneho prostredia pri metódach pokus-omyl by nemuselo dopadnúť najlepšie, hlavne pri extrémnych prípadoch, preto sa často využívajú simulačné prostredia. Okrem rizika poškodenia hardvéru simulácie môžu bežať rýchlejšie a dokonca paralelne. Pokiaľ sa snažíte nahradiť tradičné riadenie je možné, že už model prostredia dokonca máte. S využitím výpočtového prostredia MATLAB a jeho nadstavby Simulink už máte k dispozícií niekoľko možností ako prostredie vytvoriť. Napríklad môžete modelovať dynamiku vozidla, lietadla vstavanými blokmi, využiť Simscape na modelovanie fyzikálnych komponentov, alebo aproximovať dynamiku na základe dát pomocou System Identification Toolboxu.
Definícia odmeňovania
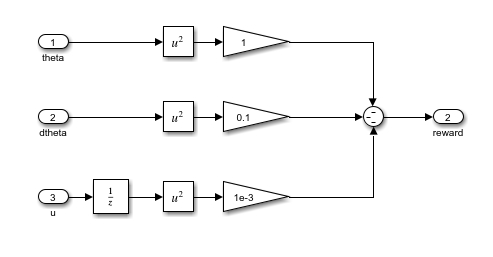
Po vytvorení prostredia je potrebné si uvedomiť, čo má agent robiť a ako ho odmeníme. Preto je potrebné vytvoriť funkciu odmeňovania, aby trénovací algoritmus vedel, kedy sa stratégia zlepšuje. Výstupom odmeňovacej funkcie je číslo (skalár), ktoré reprezentuje vhodnosť akcie v aktuálnom stave. Všeobecne funkcia vracia pozitívnu odmenu, keď chceme agenta podporiť v akcii a naopak negatívnu odmenu (pokutu), keď chceme agenta odradiť od akcie. Reinforcement learning nekladie obmedzenia na tvorbu funkcie, avšak jej návrh vzhľadom na požadovaný cieľ je jedna z najzložitejších úloh celej metódy. Inžinieri môžu využiť pri tvorbe funkcie znalosti systému, ale či je funkcia zvolená správne môžu zistiť až po niekoľkých iteráciách trénovania. V MATLABe a Simulinku môžete vytvoriť odmeňovanie ako funkciu, prípadne subsystém.
Vytvorenie agenta
Po vytvorení prostredia a definícii odmeňovania sa zvyčajne prechádza k vytvorení agenta. Ako sme už spomenuli agent sa skladá zo stratégie a učiaceho algoritmu, ktorý sa snaží nájsť optimálnu stratégiu. Stratégia je funkcia, ktorá prijíma pozorovania z prostredia a vracia akcie. Existuje niekoľko spôsobov ako takúto funkciu reprezentovať, ale najčastejšie sa používajú tabuľky, polynómy alebo neurónové siete. Veľkú popularitu si v súčasnosti získali neurónové siete, vrátane konvolučných neurónových sietí. Učiaci algoritmus môže mať niekoľko podôb, ale veľkú popularitu majú agenti typu actor-critic. MATLAB obsahuje niekoľko vstavaných algoritmov pre agentov ako je Deep Q-Network (DQN), Advantage Actor Critic (A2C), Deep Deterministic Policy Gradients (DDPG) a mnoho ďalších. Simulink obsahuje samostatný blok pre agenta. Okrem vstavaných algoritmov máte možnosť vytvoriť vlastného agenta prípadne importovať model pomocou ONNX.
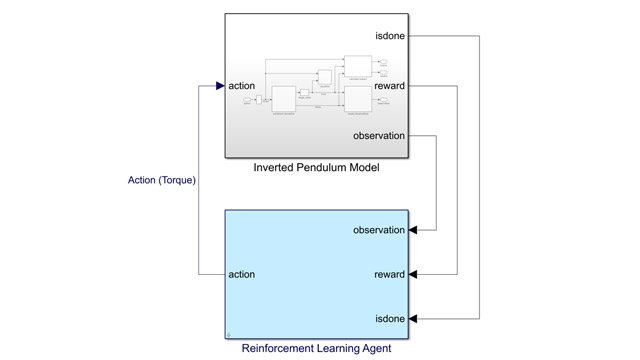
Trénovanie a jeho akcelerácia
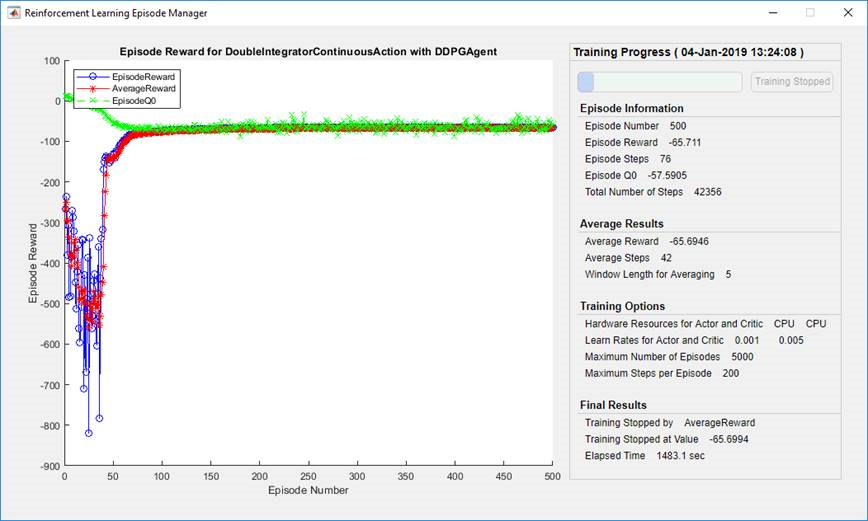
Pokiaľ máme vytvorené všetky súčasti metódy, môžeme pristúpiť k jeho trénovaniu. Reinforcement learning vyžaduje veľa dát a vo väčšine prípadov potrebuje veľa simulácií, aby natrénoval schopnú stratégiu. V tom nám pomôžu paralelné výpočty, napríklad pomocou Parallel Computing Toolboxu alebo MATLAB Parallel Servera. Trénovanie neurónových sietí môžeme realizovať pomocou Parallel Computing Toolboxu aj na GPU. Funkcia train poskytuje Reinforcement Learning Episode Manager, pomocou ktorého vieme sledovať tréningový proces vizuálne.
Nasadenie stratégie
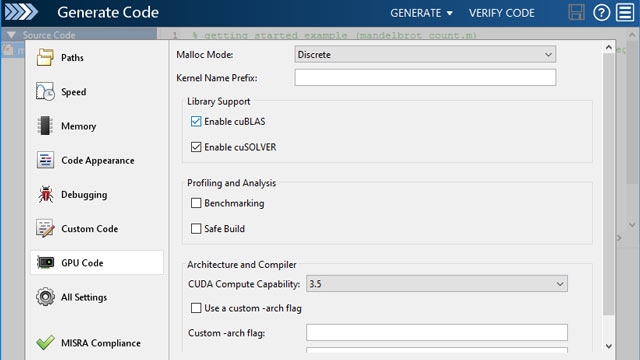
Posledným krokom reinforcement learningu je nasadenie stratégie na cieľové zariadenie, podobne ako by to bolo u klasického riadenia. Ak by bola väčšina učenia realizovaná simulačne, je niekedy potrebné pokračovať v učení aj po nasadení. Simulačné prostredie nemusí dokonale modelovať reálny svet a navyše sa časom môže meniť. Z tohto dôvodu je dobrá nasadiť aj učiaci sa algoritmus. Takto máme možnosť zapnúť alebo vypnúť učenie podľa našej potreby. Stratégie sa v MATLABe dajú konvertovať na optimalizovaný CUDA kód pomocou GPU Codera na na C/C++ kód pomocou MATLAB Codera. Navyše MATLAB Compiler a MATLAB Compiler SDK umožňuje nasadiť stratégie ako zdieľané knižnice, prípadne v jazykoch ako je .NET, Java alebo Python.
Ako začať?
Reinforcement learning obsahuje niekoľko častí, ktoré nemusia byť pre začiatočníkov s touto metódou jednoduché zostrojiť. Spoločnosť MathWorks pripravila k reinforcement learning toolboxu rozsiahlu dokumentáciu. Dokumentácia je členená na kapitoly podľa jednotlivých častí metódy, v ktorých sa viete jednoducho orientovať. Okrem dokumentácie sú k dispozícií modely prostredí v MATLABe a Simulinku, ktoré môžete využiť na testovanie rôznych typov agentov. Referenčné príklady vás prevedú kompletným návrhom v rôznych oblastiach vrátane robotiky a autonómneho riadenia áut.
Okrem dokumentácie a príkladov máte k dispozícii sériu videí na stránke MathWorks a články, ktoré popisujú jednotlivé súčasti detailnejšie.
Michal Blaho (HUMUSOFT) , 24.6.2020